The Scientists Behind Humanity's Last Exam Exposes a Massive Gap in AI Intelligence
A global team of researchers created Humanity’s Last Exam, a brutal 2,500-question benchmark designed to test the limits of artificial intelligence — and the results reveal a surprising gap between AI performance and true human expertise.

For a while, it felt like AI was winning.
Every few months, a new model would drop and somewhere in the announcement, a company would quietly mention that their system had scored higher than the average human on some standardised test.
The benchmark was getting scaled. The celebrations kept coming. And somewhere along the line, a quiet panic set in and that question starts to tug at minds: If AI can pass our exams, what exactly are we still needed for?
Then someone decided to make a harder exam, a much harder one.
In a project published in the journal Nature, nearly 1,000 researchers from across the world, from all disciplines — historians, physicists, linguists, mathematicians, medical researchers — came together to build what they are calling Humanity's Last Exam.
The name sounds dramatic, but the idea behind it is straightforward.
If today's AI systems are acing the tests we built for human learners with ease, then those tests are no longer measuring anything useful. So the researchers built one that actually would.
The result is a 2,500-question assessment covering mathematics, natural sciences, humanities, ancient languages and some of the most niche, highly specialised corners of human knowledge.

We are talking about questions that require translating ancient Palmyrene inscriptions, identifying microscopic anatomical structures in birds and analysing the fine details of Biblical Hebrew pronunciation.
These are not the kinds of things you can Google your way through and they are definitely not the kinds of things a language model can pattern-match its way to a correct answer on.
In fact, that was the entire point.
Every question submitted to the exam was first tested against leading AI systems. If any model got it right, the question was removed.
What remained was a test designed intricately to sit just beyond the reach of current artificial intelligence.
So How Did the Models Do?
The models that were tested did not do so well. GPT-4o, one of the most widely used AI models in the world, scored 2.7 percent. Claude 3.5 Sonnet reached 4.1 percent. OpenAI's o1 model did somewhat better at 8 percent.
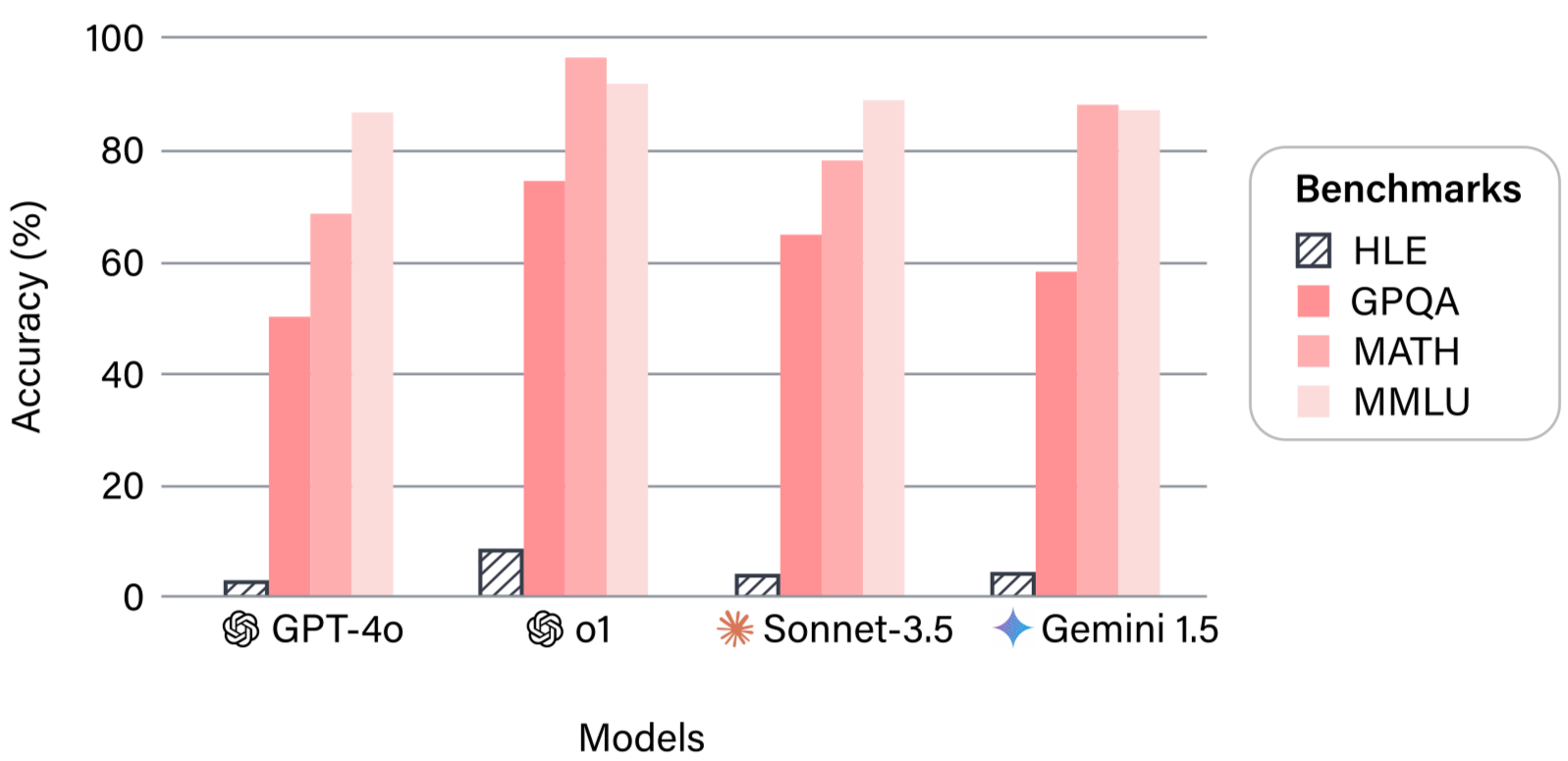
The most advanced systems tested, including more recent models, landed somewhere between 40 and 50 percent. Impressive, compared to the earlier results. Still failing, by any conventional measure.
To put that in context, a score of 40 to 50 percent on an exam where every easy question has already been filtered out is not nothing.
It suggests real capability. But it is also a long way from the kind of deep, contextual, expert-level understanding that the exam was designed to test for.
And that gap matters.
Why This Is Not Bad News

When people see numbers like these, one of two things happens.
Either they panic (AI is catching up, the machines are coming) or they dismiss the whole thing (see, AI is useless, nothing to worry about). Both reactions miss the point entirely.

What Humanity's Last Examactually demonstrates is something more complex and interesting. It clearly shows the difference between performance and understanding.
AI systems have become extraordinarily good at completing tasks. They can write, summarise, translate, code and analyse at speeds no human can match.
But intelligence, real intelligence, is not just about completing tasks. It is about depth, context and the kind of specialised expertise that comes from years of genuine engagement with a field.
Pattern recognition, which is largely what large language models are doing, breaks down when it meets questions that have no patterns to recognise.
The ancient inscription that nobody has digitised. The subspecies distinction that exists in three obscure ornithology papers. The linguistic feature that only twelve people in the world have formally studied.
These are the edges of human knowledge and they are still very much human territory.
There is also a broader implication here that tends to get lost in the noise around AI development.
Without accurate benchmarks, it becomes impossible to know what these systems can actually do and what they cannot.

Policymakers, developers, educators and everyday users make decisions based on their perception of AI capability. If that perception is inflated, the consequences range from embarrassing to genuinely dangerous.
A benchmark is infrastructure.
The Bigger Picture
What strikes me most about this project is not the scores. It is who built it.
Nearly a thousand people, from nearly every discipline and dozens of countries, worked together to expose the gaps in a technology that many assumed had already outgrown human oversight.
The irony is almost too neat: it took an enormous act of human collaboration to demonstrate just how irreplaceable human expertise still is.
AI is not losing, neither is it winning. It is a tool, a powerful and genuinely transformative one, that still has significant blind spots.
Knowing where those blind spots are is not a reason to panic. It is exactly the kind of knowledge that keeps us building better, safer and smarter.
The exam is not humanity's last word, not even close.
