Now, look, I have to admit up front that I'm biased here. I worked at Google for 4 years, and I loved it, and also I still have a little tiny bit of their stock (read: all of it), so, you know, feel free to critique my incentives if you want.
But my friends (and anyone else who lives within a five mile radius of me) can attest that I've long thought Google holds an unassailable advantage in the AI race. And on the back of their release of the latest Gemini model, creatively named "Gemini 2.5", I want to finally take a moment to write out the case in full so that if and when the stocks go up later I can have a written record of my regret for not putting more money in now.
A few months ago, on the back of the GPT Pro announcement, I wrote a recap of the then-state of AI and argued against the notion that we had reached some kind of AI performance plateau. In that post, I wrote:
Very roughly, LLM benchmark performance follows a scaling law that's a function of compute and data — exponential improvements in the number of flops (measured as the size of the model or number of training steps) and in number of "tokens" leads to linear improvements in model performance. This pattern has been tracked across many different model sizes, across nearly 7 orders of magnitude. And, anecdotally, linear improvements in model benchmark performance result in step-function improvements in real world model ability. Again, GPT2 to GPT3 was a meaningful shift. Yes, GPT3 is strictly better at generating text. But it's also picked up a bunch of other things, like being able to play chess or do basic math. […]
But in a deeper sense, the scaling laws still feel ironclad. OpenAI, Anthropic, and Meta are all investing in massive GPU superclusters. Google is too, though primarily relying on their internal TPU chipsets. Google and Microsoft are simultaneously investing in cheaper energy sources — it shouldn't be lost on anyone that both have bought access to nuclear energy — while OpenAI plans on creating its own chip designs. If you follow the money, it seems pretty clear that there's widespread belief that there's more juice left to squeeze from scale.
And much like Moore's law, there's a lot of ways in which scale can be achieved outside of raw chip quantity. Chips get better. Energy gets cheaper. We discover a new, even more efficient model architecture. We develop ways to train simultaneously on a collection of GPUs, CPUs, ASICS. Etc. People are doing research on all of these things, too.
Every AI model, large and small, is dependent on three basic ingredients.
The first is compute. This is the substrate of intelligence. You need silicon, and you need a lot of it, and it needs to be wired up in a very particular way so that you can do electric sand magic to in turn do a lot of math very quickly. For most people, this means NVIDIA GPUs.
The second is data. Increasingly it seems like you need two different kinds of datasets. The first is just broadbased masses of data, as much as possible, with no care for quality of any kind under any measure. Reddit posts? Yep. Trip Advisor reviews? Into the mix. An esperanto translation of the Canterbury Tales? Sure, why not. The suffix we are looking for here is -trillions. And the second is extremely tailored highly specific subsets of data that 'teach' the model. A few hundred thousand examples of perfect question-answer pairs, or extremely detailed reasoning traces, things like that.
And the last one, which I didn't spend as much time on in my earlier scaling post, is structure. Every model has an architecture, and the model's ability to learn is downstream of that architecture. Good architectures learn efficiently, bad architectures learn slowly — if they ever learn at all. Unlike the former two ingredients, structure is extremely difficult to measure. Like, if I have a dataset of a trillion tokens that is generally bigger (and better) than a dataset of a million tokens, and we more or less know how to go from a million to a trillion. But we have no idea how to quantitatively compare different architectures, and we cannot easily figure out how to go from a good architecture to a better one. In lieu of that, a more quantifiable ingredient is 'scientists'. That is, better AI requires a whole bunch of scientists who can figure out how to make it better.
If these three ingredients are the building blocks of artificial intelligence, they are the lifeblood of artificial intelligence companies. And all of those companies — Google, Anthropic, OpenAI, Meta, whatever — hoard their access to these three ingredients as much as they possibly can. This is why none of the papers from the large model providers indicate what data they train on or make those datasets available;1 why there was a massive NVIDIA chip supply shortage (though that seems to have abated for now); and why ML research scientist salaries have skyrocketed to well over 7 figures.
There is an obvious sense in which access to some of these resources is zero sum. Every chip owned by Meta is a chip that isn't owned by OpenAI, every researcher employed by Anthropic is (probably!) not working for Deepmind. The whole thing feels very malthusian.
So it should be no surprise that Google, with its vast reserves and nearly 2 trillion dollar valuation, has the best odds to come out ahead on all of these critical things. And I wrote as much in December:
If I had to bet on anyone here, it would be Google. They have strong vertical integration across their training stack, from chip design up to JAX. That, combined with their lack of reliance on NVIDIA, means they have access to better, cheaper, more optimized compute per flop in addition to the usual chips everyone is competing for. So far we haven't talked much about data, because the consensus is that we have way more data than what we can train on. But Google wins there too — though they've been very careful to avoid training on personal or even public-but-not-open-licensed sources, they very easily could start playing the game the way OpenAI has been when it comes to respecting IP. And even though Google hasn't opened the full data hose yet, one suspects that if they weren't under so much federal scrutiny they may have done so already.
Obviously that paragraph accounts for the compute/data side of things. What about on the research scientist side? Anecdotally, Google has been extremely aggressive in poaching from OpenAI and Anthropic, its two main competitors. The latter two companies famously offer even junior employees million-dollar-plus in total compensation. But both OpenAI and Anthropic have the small tiny problem that the vast majority of that compensation comes in the form of options, and those options are not really liquid. The lack of liquidity is a double whammy for prospective employees. First, because they cannot actually immediately sell it to, you know, pay rent or buy a sandwich. And second, and maybe most importantly, because those same employees are now stuck at the company until a liquidity event (an IPO or an exit or some round of financing) which significantly limits optionality. If Google just matches compensation directly, the liquid value of its stock is immediately preferable to any computer scientist who is even sorta financially savvy.
From first principles, of course, of course, Google is the favored candidate to win this AI race. OpenAI and Anthropic combined are worth less than $400 billion. That's not a small amount, but it's less than a fifth of what Google can throw around. And those valuations are private valuations. I've been in the startup world long enough to know that the VC price is extremely suspect.
Just to really drive the point home, it's worth comparing Google against its biggest competitor in the public sphere, OpenAI. While OpenAI has a fantastic brand and clearly knows how to deliver products,2 they are bleeding talent left and right3 and have to resort to extremely gimmicky fundraising PR stunts like Stargate to get their hands on compute. Google has never, not a single time, mentioned that it is compute capped or announced some massive headline-grabbing expansion of data centers or anything like that. It doesn't need to! Here, no news is good news. OpenAI having to stop everything to build bigger data centers will slow it down, while Google will hum quietly along until it has built god in the machine.
A naive technical leader may look at the state of things above and think "Ah, if I was Google, I would simply beat OpenAI et. al. at their own game! Take whatever OpenAI does and make it bigger, throw more compute / data / science at the problem until you win." This would certainly work, but it misses the forest for the trees. A smart technical leader would look at the state of things and think "Let's choose a game that only we can play, so we can win by default."
Google's ability to control its own destiny means it can pursue technical strategies that are simply out of scope for its competitors. This is immediately obvious if you look at the model specs for Gemini against every other flagship model.
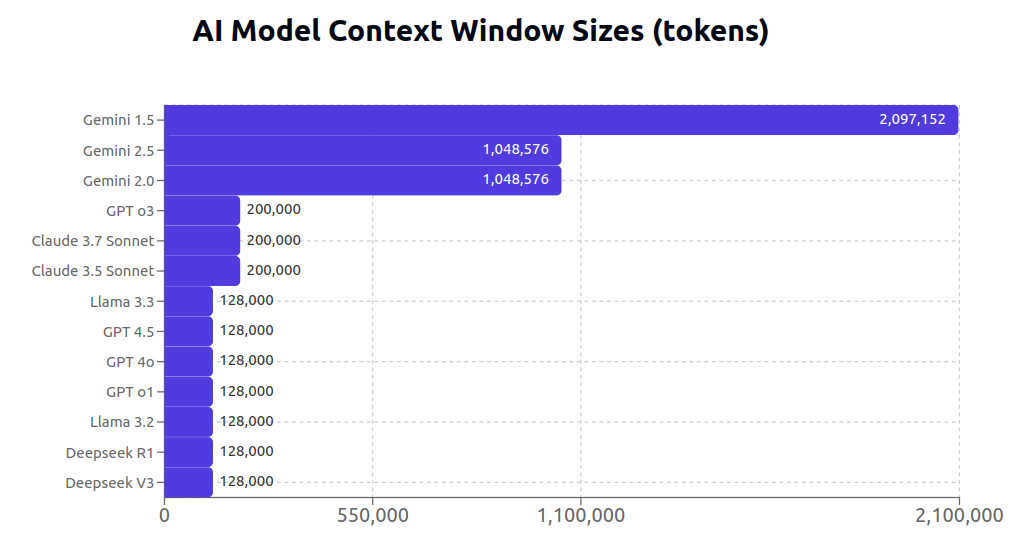
Google has been playing with large context windows for a long time, much longer than its competitors. The top models by context window are all Gemini, by a massive margin, and there is reason to believe that Google is actually sitting on research that can grow the context window to 10 million tokens.4 In fact, the only other LLM that I am aware of that even claims to have a 1M context window is Grok 3. But I only wanted to include serious LLMs in this chart, and when I asked a good SF-based friend of mine if anyone actually uses grok as a daily driver he laughed and said "no, the only thing people use grok for is if you want to make anti-woke memes", so I left it out.5
While it is immediately obvious that Google has invested in longer context windows, it is not immediately obvious why Anthropic and OpenAI have not. But to me, the answer lies in the underlying chips being used. Google's vertically integrated TPUs are extremely efficient at representing and working with large tensors, which in turn allows for matrices and matrix operations that are absolutely massive. As context window size increases, the memory complexity of the transformer increases quadratically. The reality is that even really good GPUs simply cannot compete with the TPU architecture. So Google gets twice the leverage on their TPU stack — not only does it give them economic independence from the NVIDIA chip bottleneck, it also allows them to generate unique advantages that other companies simply do not have.
I'm speculating a bit here, but I think the end game for this line of research is simply stuffing the entire internet in the context window of every single prompt or query. One of the underlying themes of my primer on deploying LLMs is that context is key to getting LLMs to do what you want. In fact, I personally think that current-generation LLMs are effectively reasoning black boxes that can do just about anything, as long as you provide the model with the right information / relevant context in the input. Well, recalling relevant information based on a query is exactly what Google has been doing for the last three decades. There is no organization in the world that has thought more deeply about thisexact problem! If Google can continue to scale up the Gemini context window size, they may be able to simply combine their preexisting search dominance with their models. This may explain why Gemini 2.0/2.5 have smaller reported context windows than Gemini 1.5. Google may already be preloading their model responses with a bunch of additional information in the prompts, just doing so behind the scenes.6
Now, credit where it is due, it is not like the other companies are just sitting around. OpenAI, Anthropic, and Deepseek are all pursuing variations of test time computation and improved reasoning models. I've written about this in the past, here:
One thing that's weird about a lot of AI models is that we expect them to behave like 'general intelligence' but do not give them time to actually reason through a problem. Many LLMs are running the American Math Competition (AMC) on 'artificially hard' mode. Except, they don't have 3 minutes to respond, they have to respond instantly. Part of why that's the case is because for a while, it was not even obvious what it meant for an LLM to 'take more time'. If you give a human a test — like the AMC — they can tell you "hey I need another minute or two to solve this problem" and do the equivalent of spending more CPU cycles on it, or whatever. More generally, a human can decide how long they need to chew on a problem before committing to an answer. LLMs can't really do that. The LLM has a fixed compute budget, determined by the size of the model and the context window (the number of tokens it can 'look at' at one time). Anything that requires more reasoning than that isn't going to work.
OpenAI has been chewing on this problem for a while, and came up with a concept they call 'inference time compute'. The earliest version of this was simply asking the LLM to show its work. Researchers discovered that if you asked an LLM to write out, step by step, how it solved a problem, accuracy went up.
More advanced inference time compute solutions include things like:
The core idea behind all of these things is to dynamically increase the amount of time and computer resources it takes for the LLM to answer the question, in exchange for accuracy. Harder questions get more compute, as determined by the LLM. This technology has been behind OpenAI's O-series models, including the latest public o1 model and the very-impressive-but-still-private o3 model.
This is, without a doubt, impressive technology. It has clearly led to significant improvements in model response quality.
But I am pretty certain OpenAI pioneered this direction precisely because they were feeling the pinch of their compute limitations. Test-time compute trades hardware usage for wall-clock time — you can run OpenAI's models on fewer GPUs or even CPUs, but it will take longer. If you don't have that many GPUs to begin with, test-time compute is a much more hardware efficient research area than simply scaling your models. It shouldn't be a surprise, then, that the first test time compute models came out right around the time GPUs were incredibly sparse, and it was unclear whether anyone in the entire country had data centers large enough to 10x the size of GPT4.
In any case, impressive though the technology may have been, it was also clearly replicable. Even though OpenAI did not publish the techniques that led to O1, Deepseek was able to figure out how to get a competitive reasoning model anyway. The reality is that the big tech companies are extremely leaky when it comes to IP, publications or not. Researchers are constantly switching between OpenAI, Meta, Anthropic, and Google. And some of those people are probably foreign national spies who are sending information back to the motherland anyway. In that kind of environment, technical advantages that depend on secrecy can only last for so long — it is just too easy for the other labs to simply copy and incorporate the latest advancements. I wrote as much in my review of the S1 paper.
The research being done by labs both big and small are, for the most part, not mutually exclusive. Advancements are coming in a variety of complementary forms that drive the entire industry and experience forward.
A good metaphor for this kind of advancement is Moore's law. Very roughly, Moore's law states that the number of transistors on a chip should double roughly every two years.
Moore's law does not make assumptions about where those gains are coming from. Moore didn't say something like "chip capacity will double because we're going to get really good at soldering" or whatever. He left it open. And in fact in the 60-odd years since Gordon Moore originally laid out his thesis, we've observed that the doubling of transistors came from all sorts of places — better materials science, better manufacturing, better understanding of physics, all in addition to the (obvious) better chip design.
You can imagine a kind of Moore's law for intelligence, too. We might expect artificial intelligence to double along some axis every year. Naively we'd expect that improvement to be downstream of more data and more compute. But it could also come from better quality data collection, more efficient deep learning architectures, more time spent on inference, and, yes, better prompting.
It's amazing that the S1 researchers were able to compete with both O1 and Deepseek on basically no budget. The authors should win all the awards, or at least get some very lucrative job offers. In my opinion, though, the really beautiful thing about the S1 paper is that everyone else can immediately implement the S1 prompt engineering innovations to make their own models better.
If you can't build a moat around IP, you have to build a moat around something else, or die to the competition. You may see where I am going with this: because Google's innovations depend on their deep integration with the TPU stack, they cannot be easily copied even if the underlying implementation details are leaked. This means that Google can easily copy OpenAI's research, but OpenAI cannot easily copy Google's.
And yet, even though I’ve just written a billion words about how Google should be super far ahead of the herd, the conventional wisdom is that Gemini sucks!
Throughout 2021 to 2023, OpenAI had the clear lead, both in terms of LLM benchmarks and in terms of lived experience. Everyone I knew used variants of the GPT models, they were simply the best game in town. Near the end of 2023, Anthropic really started to pick up steam. Anthropic's Claude family of models were often wrapped in a better UX, which made them more pleasant to work with. And the release of Sonnet 3.5 seriously turbo-charged Anthropic's code generation ability, making Anthropic the go-to model for Silicon Valley. That has continued with the release of Claude 3.7, which is now the default for many code generation platforms including Replit and Cursor.
Even Meta's Llama series had more users than Gemini! Because Llama is open source, the die-hard privacy folks, the tinkerers and researchers, and the hackers all lined up to build in the llama ecosystem. Even though Llama was, by all accounts, worse than Gemini.
Some of Gemini's early weaknesses can be chalked up to poor leadership. Google really was caught unawares by OpenAI's surprise dominance, and it was clear that they were in reactive-mode from at least 2021 to 2023. The overall chaos of the time period was exacerbated by poor messaging about their demos and an overall high friction user experience that prevents adoption and, frankly, plagues much of the GCP suite.
Over time, Gemini did manage to carve out a niche for itself. It is by far the cheapest of the LLMs, meaningfully faster than Claude or OpenAI, and often has better rate limit policies. As a result, some developers reached for Gemini for low hanging fruit inference tasks. But it was a pretty small piece of the overall pie. I've said multiple times that the LLM provider market has strong winner-take-all effects:
Going back to LLMs, I think you see roughly the same market dynamics. LLMs are pretty easy to make, lots of people know how to do it — you learn how in any CS program worth a damn. But there are massive economies of scale (GPUs, data access) that make it hard for newcomers to compete, and using an LLM is effectively free so consumers have no stickiness and will always go for the best option. You may eventually see one or two niche LLM providers, like our LexusNexus above. But for the average person these don't matter at all; the big money is in becoming the LLM layer of the Internet.
As long as Gemini wasn't the best model, it didn't really matter that it was a sorta cheaper model. The cost per token is so low anyway that the average developer — and certainly the average consumer — just didn't care.
But that was a week ago.
Three days ago, Google released Gemini 2.5. And though it is still early, the benchmark results seem to be really good.
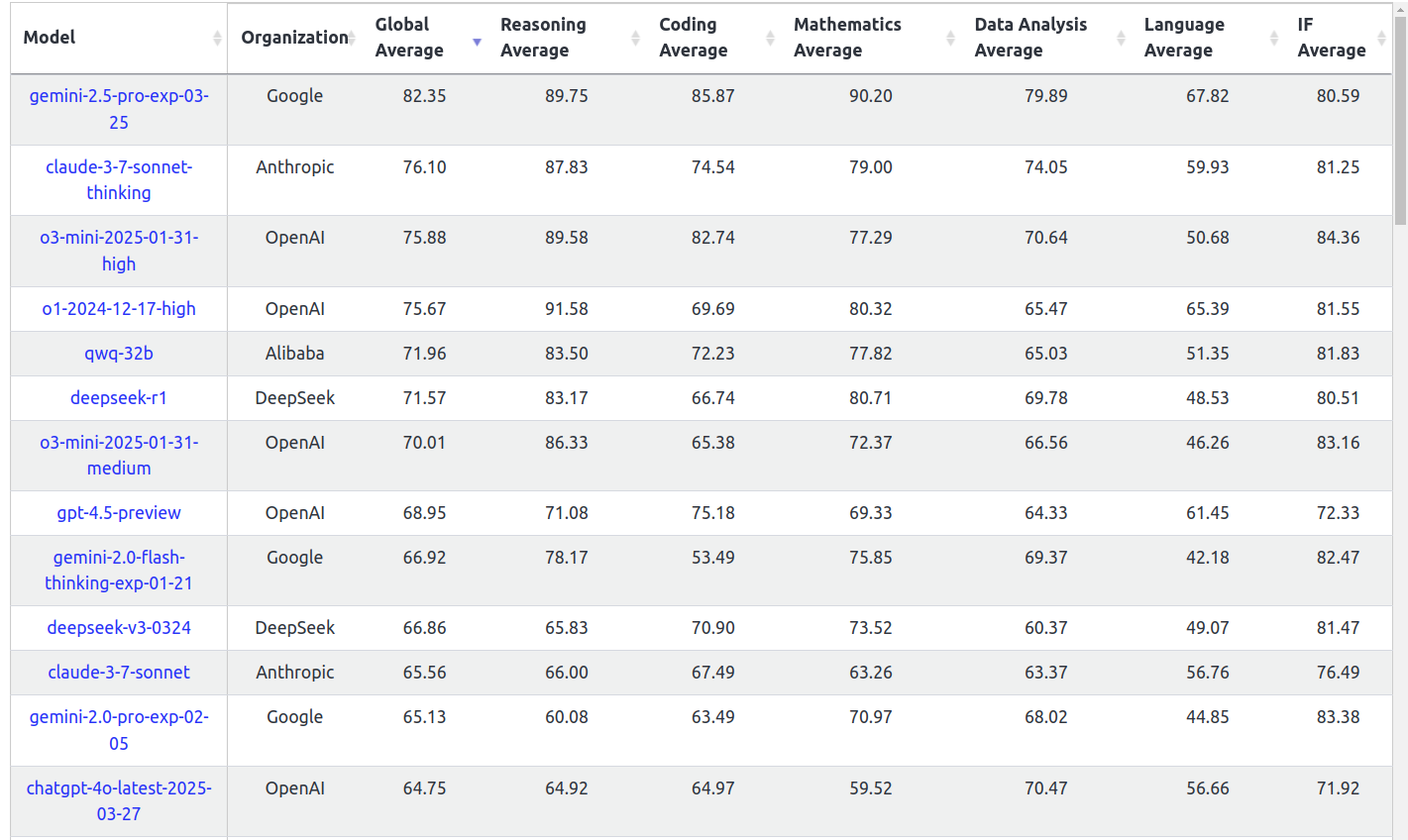
But of course every real ML practitioner knows that benchmarks can be gamed. What do the people say?
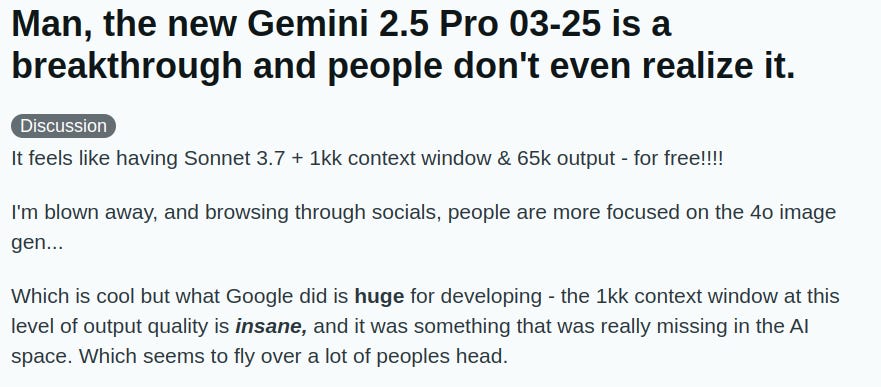
Yea, I think the people are happy. It's still not super clear what exactly is the secret sauce powering Google's new model, but suffice to say there's something real here.
OpenAI is known for mocking Google by scheduling new product releases the day after Google announces basically anything. And this release was no exception — OpenAI released 4o image gen, which is fairly powerful and very controversial. But as the anonymous reddit poster hints at above, though the image gen is interesting and provides for easy viral content, it's not particularly new and not nearly as impressive as the Gemini release, at least to anyone paying attention. OpenAI's newest model release, GPT 4.5, did not inspire significant confidence. And though they have already announced o3 and released o3-mini, the fact that they did not simply release the bigger o3 model suggests that they may still be behind where Gemini is.
This is something of a first for Google. As far as I can remember, the Gemini series has never meaningfully been in the lead in such a commanding way. The obvious next question is whether they can maintain that lead, and the question after that is whether they can actually, like, figure out how to market the thing.
But here too, Google has significant advantages. I have yet to touch on the one area where Google absolutely dominates everyone else: distribution. Google owns the applications (docs, maps, email). Google owns the data (email, drive, bigquery). Google owns the browser. And Google owns Android. Losing search dominance is a big deal and should not be downplayed, but it is only an issue if they actually losing search dominance. If people end up going to Gemini instead of search, it's not nearly as big a deal, because all of search is still happening in the Google ecosystem. That's the real prize that everyone is after from a commercialization perspective.
In the end, I can't say for certain that Google is going to "win" (in part because it is increasingly less clear to me what 'winning' even entails — more on this later). But I was always pretty confident that Google would do well, and was always confused about why my expectations didn’t line up with reality. It’s nice to finally see Google actually throwing their weight around and putting their money and resources to good use.










